Windows下tesseract-ocr的安装、使用、训练
tesseract-ocr
OCR : 光学字符识别(Optical character recognition),是将打字,手写或印刷的文本图像转换成计算机文本。输入可以是扫描的文档,文档的照片,还是场景的照片(身份证照片、驾驶证、广告牌)。
Tesseract:开源的OCR引擎,在Apache 2.0协议下可用。
安装
下载地址,我当前下载的版本是tesseract-ocr-w32-setup-v4.1.0.20190314.exe,按照步骤安装就行。我的安装路径是E:\Tesseract-OCR。
用命令行工具测试一下
1 | $ tesseract tesseract-ocr-1.png tesseract-ocr-1.output |
我输入的图片是

输出的结果 tesseract-ocr-1.output.txt中的文本是
1 | tesseract-ocr |
可以直接输出到stdout
1 | $ tesseract tesseract-ocr-1.png stdout |
可以添加-l选项指定语言,如果不指定,默认是eng.
默认安装后,语言列表仅有eng和osd。
1 | $ tesseract --list-langs |
训练
我们有如下一张图片,进行识别
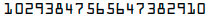
1 | $ tesseract tesseract-ocr-2.png stdout |
识别的结果显然不是我们想要的,接下来我们对它进行训练。
使用在线工具将jpg转换成tiff格式,重命名为
l2m2hw.normal.exp0.tif。tiff命名规则:
${lang}.${fontname}.exp${num}生成box文件
1
2
3
4$ tesseract --psm 6 --oem 3 l2m2hw.normal.exp0.tif l2m2hw.normal.exp0 makebox
Tesseract Open Source OCR Engine v4.0.0.20190314 with Leptonica
Page 1
Warning: Invalid resolution 0 dpi. Using 70 instead.通过帮助命令可以查看psm和oem参数的可选项及含义
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23$ tesseract --help-psm
Page segmentation modes:
0 Orientation and script detection (OSD) only.
1 Automatic page segmentation with OSD.
2 Automatic page segmentation, but no OSD, or OCR. (not implemented)
3 Fully automatic page segmentation, but no OSD. (Default)
4 Assume a single column of text of variable sizes.
5 Assume a single uniform block of vertically aligned text.
6 Assume a single uniform block of text.
7 Treat the image as a single text line.
8 Treat the image as a single word.
9 Treat the image as a single word in a circle.
10 Treat the image as a single character.
11 Sparse text. Find as much text as possible in no particular order.
12 Sparse text with OSD.
13 Raw line. Treat the image as a single text line,
bypassing hacks that are Tesseract-specific.
$ tesseract --help-oem
OCR Engine modes:
0 Legacy engine only.
1 Neural nets LSTM engine only.
2 Legacy + LSTM engines.
3 Default, based on what is available.打开jTessBoxEditor (运行E:\jTessBoxEditor\training.bat),
Box Editor->Open, 选择刚才生成的tif文件。jTessBoxEditor是训练Tesseract的辅助工具。下载地址。我当前下载的版本是2.3.1。
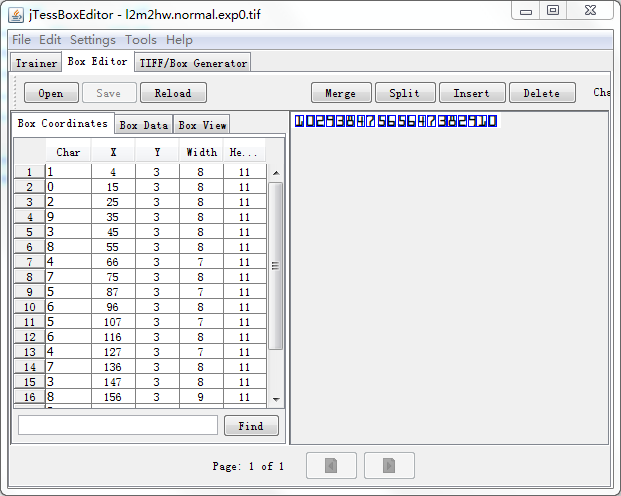
在左侧修正字符后,保存
创建font_properties文件
1
$ echo normal 0 0 0 0 0> font_properties
语法:
<fontname> <italic> <bold> <fixed> <serif> <fraktur>到这一步,你应该有这些文件:
1
2$ ls
font_properties l2m2hw.normal.exp0.box l2m2hw.normal.exp0.tif生成训练文件 .tr
1
2
3
4
5
6
7
8
9$ tesseract l2m2hw.normal.exp0.tif l2m2hw.normal.exp0 nobatch box.train
Tesseract Open Source OCR Engine v4.0.0.20190314 with Leptonica
Page 1
Warning: Invalid resolution 0 dpi. Using 70 instead.
Estimating resolution as 147
APPLY_BOXES:
Boxes read from boxfile: 20
Found 20 good blobs.
Generated training data for 2 words生成unicharset字符集文件
1
2
3$ unicharset_extractor l2m2hw.normal.exp0.box
Extracting unicharset from box file l2m2hw.normal.exp0.box
Wrote unicharset file unicharset生成特征字符文件
1
2
3
4
5
6$ mftraining -F font_properties -U unicharset -O l2m2hw.unichaset l2m2hw.normal.exp0.tr
Done!
Read shape table shapetable of 10 shapes
Reading l2m2hw.normal.exp0.tr ...
Warning: no protos/configs for Joined in CreateIntTemplates()
Warning: no protos/configs for |Broken|0|1 in CreateIntTemplates()生成字符正常化特征文件 normproto
1
2
3
4
5$ cntraining l2m2hw.normal.exp0.tr
Reading l2m2hw.normal.exp0.tr ...
Clustering ...
Writing normproto ...到这一步,你有这些文件了。
1
2
3
4$ ls
font_properties l2m2hw.normal.exp0.tif normproto unicharset
inttemp l2m2hw.normal.exp0.tr pffmtable
l2m2hw.normal.exp0.box l2m2hw.unichaset shapetable重命名文件
1
2
3
4
5$ mv inttemp l2m2hw.inttemp
$ mv normproto l2m2hw.normproto
$ mv pffmtable l2m2hw.pffmtable
$ mv shapetable l2m2hw.shapetable
$ mv unicharset l2m2hw.unicharset合并训练文件
1
2
3
4
5
6
7
8
9
10$ combine_tessdata l2m2hw.
Combining tessdata files
Output l2m2hw.traineddata created successfully.
Version string:v4.0.0.20190314
1:unicharset:size=721, offset=192
3:inttemp:size=134520, offset=913
4:pffmtable:size=110, offset=135433
5:normproto:size=1382, offset=135543
13:shapetable:size=184, offset=136925
23:version:size=15, offset=137109
测试l2m2hw训练库
拷贝训练库到安装目录的tessdata下
1
$ cp l2m2hw.traineddata /e/Tesseract-OCR/tessdata/
再次识别
1
2
3
4
5$ tesseract tesseract-ocr-2.png stdout -l l2m2hw
10293847 565647382910
Warning: Invalid resolution 0 dpi. Using 70 instead.
Estimating resolution as 147正确啦!